Previously to take down this wordpress site all you needed to do was hold down F5 for about 20 seconds then the site would take about 5 mins to recover.
There were a few factors causing this and quite a few different methods to solving the problem. WordPress itself is run on php / apache, apache has an evasive mod which can block certain IPs depending on the defined abusive behavior (typical DDOS attack). Since i like to run a few websites behind a single IP i looked at fixing the issue closer to the perimeter….
Enter nginx (engine x) as a reverse proxy, the site now typically caches all content and serves it straight out of memory. No longer does mysql / apache kill itself under high load on the backend…

You will need to create the nginx directories if they dont already exist. Check /var/log/nginx/error.log (default ubuntu) if any issues starting the service.
sudo aptitude install nginx
sudo service nginx start
The following added to http {}
(located in /etc/nginx/nginx.conf)
log_format cache '***$time_local '
'$remote_addr '
'$upstream_cache_status '
'Cache-Control: $upstream_http_cache_control '
'Expires: $upstream_http_expires '
'"$request" ($status) ';
access_log /var/log/nginx/access.log cache;
error_log /var/log/nginx/error.log;
server_names_hash_bucket_size 64;
proxy_cache_path /var/www/nginx_cache levels=1:2
keys_zone=one:10m
max_size=1g inactive=30m;
proxy_temp_path /var/www/nginx_temp;
the following added to location / {}
(located in /etc/nginx/sites-enabled/default)
proxy_pass http://sigtar;
proxy_next_upstream error timeout invalid_header http_500 http_502 http_503 http_504;
proxy_redirect off;
proxy_buffering on;
proxy_buffer_size 16k;
proxy_buffers 32 16k;
proxy_cache one;
proxy_cache_valid 200 302 304 10m;
proxy_cache_valid 301 1h;
proxy_cache_valid any 1m;
client_body_buffer_size 128k;
proxy_busy_buffers_size 64k;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_pass_header Set-Cookie;
Note if you have problems with wordpress redirect issues… check this post;
http://tommcfarlin.com/resolving-the-wordpress-multisite-redirect-loop/
Also confirm you have this line in http {}
server_names_hash_bucket_size 64;
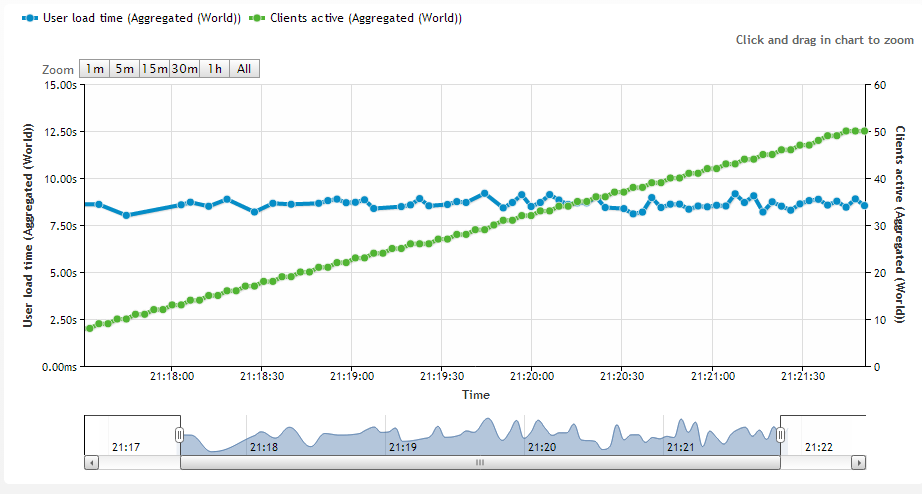
Very basic load test, user load time is reasonably consistent as user count increases.
http://loadimpact.com/load-test/sigtar.com-ad07b7870a75c854a935752b0a032c53