By hooking up my ATS in my solar system, I’m nearing the end of my solar experiment. I cannot recommend the ATS (automatic transfer system) more, such a brillient device.
By installing the ATS i am keeping my solar power generated off grid, but with on grid backup for any loads i attach to it. Also keeps me away from any danger introduced by back filling the grid
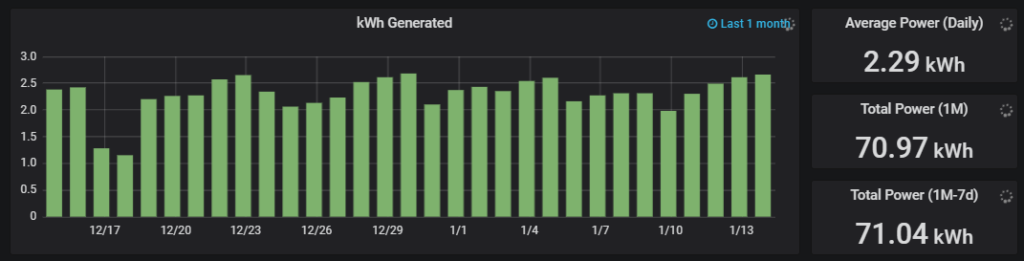
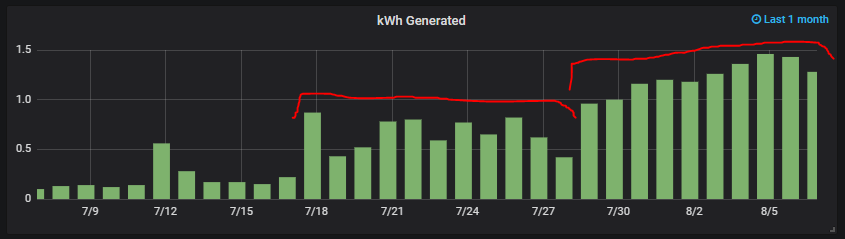
So i can run a 24/7 load which will automatically flick over to main power when the batteries are low. At the moment i am powering my attached server (the load) approx 33% of the day. I could power my server for longer if i had a larger battery attached to solar. Its currently winter, so sunlight hours are also limited.
Check out this video for more – https://www.youtube.com/watch?v=ni0A_ZdH7aU.
ATS on Ali Express – https://bit.ly/2O63Hq4
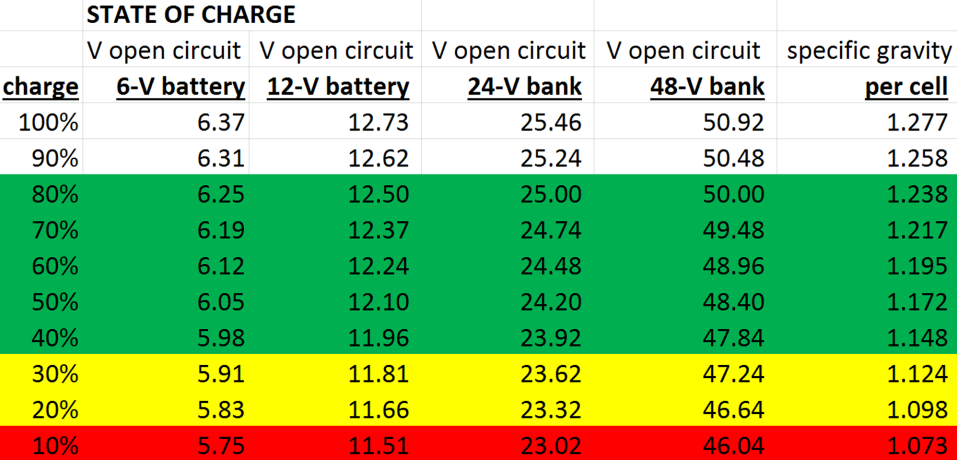
I’m running a 24v lead acid (yuck) battery. I have setup the LV (low voltage) cut over to 24.0V. Keep in mind that under load there is a voltage drop so when the ATS flicks back to mains the battery actually jumps back to about 24.5V (over 50% DOD).
My HV (high voltage) is set to 29.0V, this is voltage when not under load. Again lead acid batteries like to be fully charged, so i have to take this quite high to ensure longer life of my battery.
Note : Running UNRAID server also helps, each disk while not being used will power down reducing my power draw. The unique RAID also means that all disks do not need to spin up on data access (non distributed parity). Friken cool!
Disclaimer : This dabbles with high voltage, please do NOT attempt install without certified assistance. Electricity is dangerous!